


Large areas of the global lands do not have access to daily streamflow rate measurements. However, predictions in these regions are still essential to understanding the global water cycle and mitigating the impacts of climate change. Deep learning models like the long short-term memory (LSTM) network have recently become powerful tools in hydrologic modeling. Many studies show the LSTM model can vastly outperform traditional physical models. However, if we extrapolate DL-based hydrologic models calibrated elsewhere to those large ungauged regions, how reliable are they?
Previously, hydrologists mainly studied the prediction in ungauged basins (PUB) problem, where a targeted basin needing predictions can be represented by neighboring or similar basins. There has not been ample recognition that prediction in large, contiguously data-sparse regions, which we call prediction in ungauged regions (PUR), is a more complex problem than PUB. With neighboring donors, PUB belongs to the problem of spatial interpolation, while PUR is essentially spatial extrapolation. In this study, we proposed the PUR problem and evaluated the performance of the LSTM streamflow model when extrapolated to large ungauged regions. We used a dataset with 671 US basins and divided the whole CONUS into seven PUR regions. Each time one region was held out for testing during model training, and we did cross-validation to get the spatial out-of-sample predictions for all seven regions.
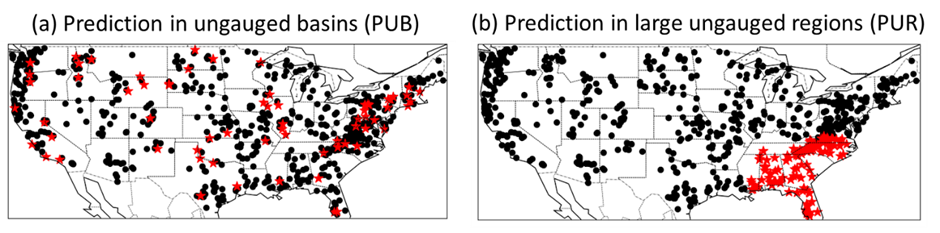
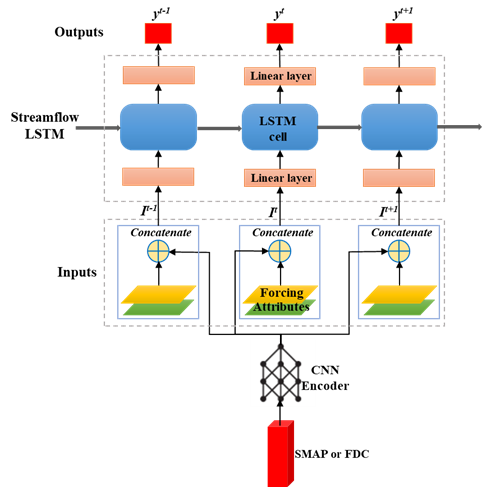
The results show that significant risk exists for DL models when applied to spatial extrapolation. The performance drops a lot from the PUB to the PUR scenario. However, is there any strategy to reduce the potential risk of DL models for extrapolation? We proposed several pathways. The first is using the “input-selection ensemble,” which means we build several models with different configurations of basin attribute inputs and use the average prediction from all these models. This ensemble method could reduce the potential overfitting of the models to the attribute inputs and improve the generalizability to ungauged regions with non-similar attributes. The second is assimilating the auxiliary information more accessible to obtain to constrain the predictions from extrapolation. For example, in ungauged regions, we could always get the soil moisture information from satellite observations. In some regions, accessing daily discharge data is difficult, but possible to acquire flow duration information. This strategy uses the DL models’ flexibility to integrate multi-type information. We developed an assimilation kernel, essentially a convolutional neural network (CNN), to integrate the auxiliary information. These strategies largely mitigated the prediction error and improved the PUR performance.
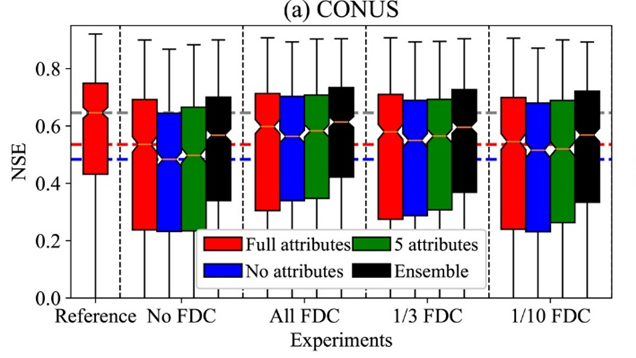
To summarize, prediction in large ungauged regions (PUR) is needed to describe and quantify the global water cycle but presents perhaps one of the toughest challenges to hydrologic modeling. The fundamental uncertainties of the DL hydrologic model applied to contiguously data-sparse regions have been overlooked to some extent, which is much greater than those reported in previous PUB studies with dense neighbor representations. We should carefully examine the DL model characteristics when applying them to spatial extrapolation. Although the potential risk exists, this study also proposed a path toward reducing risks and obtaining performant models by utilizing DL algorithms, error mitigation techniques, and additional datasets.
Reference
Feng, D., Lawson, K., & Shen, C. (2021). Mitigating prediction error of deep learning streamflow models in large data-sparse regions with ensemble modeling and soft data. Geophysical Research Letters, 48, e2021GL092999. https://doi.org/10.1029/2021GL092999
This article was originally on Medium (https://medium.com/@psuwaterstudentgroup/streamflow-prediction-in-large-ungauged-regions-with-deep-learning-models-53d66eb805dd) and was republished with permission.


